
傾向スコア、色んな所で多用されています。
わりと簡単にできるし、特に傾向スコアマッチングは見た目と使い勝手が良いです。
しかし、そもそも
「なぜ傾向スコアを使う(必要がある)か」
考えたことはあるでしょうか。
普通の多変量解析ではだめなのでしょうか。
この記事では、「傾向スコアを使う前に知っておくべき事」のうち、特に重要な5つのポイントを紹介します。
使う前に必ず抑えてください。
Contents
傾向スコアを使う前に知っておくべき事 TOP 5

傾向スコアって何のために使うのでしょうか。
交絡因子を調整するためですね(詳細はこの記事にて)。
でも交絡因子を調整する方法って、他にもあります。
→普通の多変量解析、IPW、standardization、G estimation、IV estimationなどなど
その中で、なんで傾向スコアを使う(必要がある)のでしょうか。
例えば、よく、傾向スコアマッチングは
「ランダム化試験みたいに介入群とコントロール群を作れるから良い」
と言われます。
残念ながら、これは誤りです。
*********
傾向スコア、使いたくなる気持ちは分かります。
しかし使う前に、大事なことがあります。
そのうち、自分が勝手に決めたTOP 5:
1. 傾向スコアのモデルに使う変数は論理的に決める
2. 傾向スコアマッチングはランダム化試験の代わりになるはずがない
3. マッチングしてしまう事が、因果推論の原理原則に沿わない
4. 傾向スコアを使うべき状況は決まっている:多変量解析でoverfitとなる時
5. 傾向スコアの使いみちはマッチングだけでない
これを順に説明していきます。
1: 傾向スコアのモデルに使う変数は論理的に決める
傾向スコアのモデルとは、
介入因子(暴露因子)= 変数1 + 変数2 + ・・・・
というモデルです。
これから傾向スコアを算出しますね。
結論から言うと、このモデルで右辺に使う変数は交絡因子であるべきなのです。
なぜなら、傾向スコアは観察研究で因果推論を行う手法の一つだから(観察研究での因果推論についてはこちら)。
交絡因子は論理的に決められるべきです(統計的には決めるべきでない:詳細こちら)
*よく誤解されている方法に、傾向スコアのモデルのC統計量が高いほうが良い、というものがあります。
C統計量とは、ROC曲線がどれくらい良いか=どれくらい「介入(暴露因子)のあり/なし」をdiscriminationできているか、を示します。
なんとなく高ければ高いほど方が良さそうですが、そうとは限りません。
なぜなら、
1:どれくらい高ければOKか、誰も知らない
2:C統計量は、どれだけ交絡因子を調整できているかの指標にはならない
3:もしC統計量=1だったら、介入群と非介入群が完全に別の集団であることを意味する。そしたらその2群を比べる意味が無い。
ということで、傾向スコアのモデルに使う変数は(通常通り)論理的に決めましょう。
ただ、モデルの選択については別に気をつける必要があります。
傾向スコアのモデルはflexibleである方がよい
傾向スコアに使う因子は「論理的に決める」べきなのですが、
モデル自体はflexibleである方が良いです
≒ 機械学習モデルの方がよいです。
これは比較的にあまり知られておらず、よくlogistic regressionが傾向スコアモデルに使われますが、それだと傾向スコアの予測性能が概して悪いです(=傾向スコアをよく反映しません)。
random forestなど、パフォーマンスの良い機械学習モデルがベターです。
2: 傾向スコアマッチングはランダム化試験の代わりになるはずがない
当たり前ですが。。
もしそうだったらコストかけてランダム化試験やらないですよね。
例えば、アスピリンと5年後の心筋梗塞発症の因果関係が知りたいとします。
一番効果的な方法はランダム化試験を組むことですが、そんなお金はありません。
手元にコホート研究のデータがあるので、それを使ってみようと思います。
交絡因子は、年齢、性別、人種、心血管病の既往、BMIを考えたとします。
傾向スコアのモデルは、
アスピリン使用有無=年齢+性別+人種+心血管病の既往+BMI
となりますね。
これで傾向スコアが算出され、例えばcaliper=0.05でマッチングし、n=1000ずつのデータが出来上がりました。
*caliperとは、傾向スコア一致とするためにどの程度のスコアのずれを許容するか
これが2000人をランダム化した研究と何が異なるか。
当然・・・・、
マッチングした集団は、マッチングした因子しか調整されていません。
ランダム化の素晴らしい所は、全ての因子が2群にランダムに分けられることです。
例えば「健康意識」:健康意識は数量化できないので、マッチングで合わせることはできませんね。ランダム化試験では2群に均等に分配されます。
3: マッチングしてしまう事が、因果推論の原理原則に沿わない
更に言うと、マッチングの過程でかなりの人数が削られていますよね。
これは
解析結果が当てはまる対象集団が限定的である
ことを直接的に表しています。
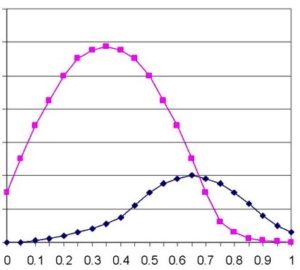
ピンクがコントロール、黒が治療群(のPS)。
だいたいこんな感じの分布になりますよね。
治療群の傾向スコア(PS)が概して高く、非治療群のPSは低い。当然です。
これをマッチングすると、多くの低いPSの非治療群、多くの高いPSの治療群が除外されます。
つまり、「PSがまあまあ」という集団に限定されてしまうわけです。
ところで、、
「PSがまあまあ」とはどういう集団なんでしょうか?
誰にもイメージつきませんよね。
マッチングした集団で、「アスピリンのリスク比が0.8だった」と結論しても、それが当てはまる集団は「PSがまあまあ」の人達です。
つまり解釈不可能です。
*例えば日本の研究は「対象が日本人」という強いselectionがかかりますが、これは解釈可能ですね。
以上より、傾向スコアマッチングは因果推論の原理原則に沿わないのです。
厳密には使うべきでありません(とMiguel先生が言っていました)。
*なお、これは「対象集団のselection」であり、疫学的には「selection bias」ではありません。
4: 傾向スコアを使うべき状況は決まっている:多変量解析でoverfitとなる時
傾向スコアは、多変量解析と並ぶ、因果推論の一つの方法に過ぎません。
そして、多変量解析より傾向スコアが好ましい場合は、かなり限られています。
それは・・
「多変量解析でoverfitとなる時(そして傾向スコアモデルがoverfitとならない時)」
です。
傾倒スコア解析と多変量ロジスティック回帰、どちらを選ぶべきか検討された研究を紹介します(AJE 2003;158:280-287.)。
ロジスティック回帰は、モデルに含む因子がアウトカムの個数÷10くらいより多いとoverfitとなり精度が下がる事が有名ですね。
この論文では、
ロジスティック回帰の因子がアウトカムの個数÷7より多い場合、そのロジスティック回帰よりも傾向スコア解析の方が良い
と結論されています。
そうでない場合はどちらを使っても変わらないと。
例えば、イベント発生が1000人中50の場合。
50÷7 = 7.1なので、
暴露因子+交絡因子の数が8個以上なら、傾向スコア解析の方が良い。
暴露因子+交絡因子の数が7個以下なら、普通のロジスティック回帰も傾向スコア分析も変わらない。変わらないならロジスティック回帰を使うべき。
という事です。
なぜか?
当然ながら、傾向スコアモデルはoverfitになりにくいからです。
1000人中50人しかイベント発生していなくとも、「暴露因子あり」は400人くらいいるのが普通ですね。
傾向スコアモデルは、「暴露因子ありなし=交絡因子」なので、交絡因子を沢山入れることができます。
この場合は40個も。
5: 傾向スコアの使いみちはマッチングだけでない
ちなみに。
傾向スコアを使うべき状況がわかった上で、その使いみちはマッチングだけでない事を知っておきましょう。
使い方は次の3つ:
・マッチング
・調整因子として使う
・weight計算用に使う
マッチングは説明しましたね。先程説明したlimitationが大事です。
裏返すとこのassumptionは、「マッチした人において算出された治療効果=マッチされなかった人における治療効果」となります。
通常、ほぼ当てはまりませんね。
調整因子として使えることは、案外知られていません。
イベント=暴露因子+PS
とするだけです。
より厳密にやりたい場合は、+PS2もつけるとよいです。
この方法のassumptionは、「effect modificationがない」ということです。
PS計算した時点でeffect modificationは検討できないですね。
(effect modification, interactionについてはこちら)
PSをweight計算用に使うこともできます。
Inverse probability weighting(IPW)の方法ですね。
結論
実は傾向スコアを使うべき状況は限られています。
使いみちもマッチングだけではないです。
もしかしたらマッチングは最もlimitationの強い、悪手かもしれません。
ではまた。